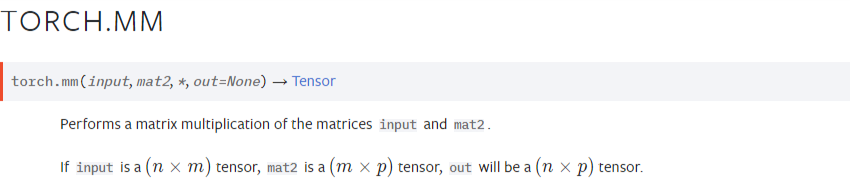
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| import torch
import torch.nn.functional as F
class BiLSTMAttn(torch.nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size, num_layers, num_classes):
super(BiLSTMAttn, self).__init__()
self.embedding = torch.nn.Embedding(vocab_size, embed_size)
self.lstm = torch.nn.LSTM(embed_size, hidden_size, num_layers=num_layers, batch_first=True, bidirectional=True)
self.attention_weights_layer = torch.nn.Sequential(
torch.nn.Linear(hidden_size, hidden_size),
torch.nn.ReLU(inplace=True)
)
self.liner = torch.nn.Linear(hidden_size, num_classes)
self.softmax = torch.nn.Softmax(dim=1)
def forward(self, inputs):
emb = self.embedding(inputs)
output, (hidden, _) = self.lstm(emb)
"""将双向lstm的输出拆分为前向输出和后向输出"""
(forward_out, backward_out) = torch.chunk(output, 2, dim=2)
out = forward_out + backward_out
hidden = hidden.permute(1, 0, 2)
hidden = torch.sum(hidden, dim=1)
hidden = hidden.squeeze(dim=1)
"""用hidden生成attention的权重"""
attention_w = self.attention_weights_layer(hidden)
attention_w = attention_w.unsqueeze(dim=1)
attention_context = torch.bmm(attention_w, out.transpose(1, 2))
softmax_w = F.softmax(attention_context, dim=-1)
out = torch.bmm(softmax_w, out)
out = out.squeeze(dim=1)
out = F.softmax(self.linear(hidden), dim=1)
return out
|